App Indexing updates
Webmaster Level: Advanced

In October, we announced guidelines for App Indexing for deep linking directly from Google Search results to your Android app. Thanks to all of you that have expressed interest. We’ve just enabled 20+ additional applications that users will soon see app deep links for in Search Results, and starting today we’re making app deep links to English content available globally.
We’re continuing to onboard more publishers in all languages. If you haven’t added deep link support to your Android app or specified these links on your website or in your Sitemaps, please do so and then notify us by filling out this form.
Here are some best practices to consider when adding deep links to your sitemap or website:
- App deep links should only be included for canonical web URLs.
- Remember to specify an app deep link for your homepage.
- Not all website URLs in a Sitemap need to have a corresponding app deep link. Do not include app deep links that aren’t supported by your app.
- If you are a news site and use News Sitemaps, be sure to include your deep link annotations in the News Sitemaps, as well as your general Sitemaps.
- Don’t provide annotations for deep links that execute native ARM code. This enables app indexing to work for all platforms
When Google indexes content from your app, your app will need to make HTTP requests that it usually makes under normal operation. These requests will appear to your servers as originating from Googlebot. Therefore, your server’s robots.txt file must be configured properly to allow these requests.
Finally, please make sure the back button behavior of your app leads directly back to the search results page.
For more details on implementation, visit our updated developer guidelines. And, as always, you can ask questions on the mobile section of our webmaster forum.
Posted by Michael Xu, Software Engineer

More Precise Index Status Data for Your Site Variations
Webmaster Level: Intermediate
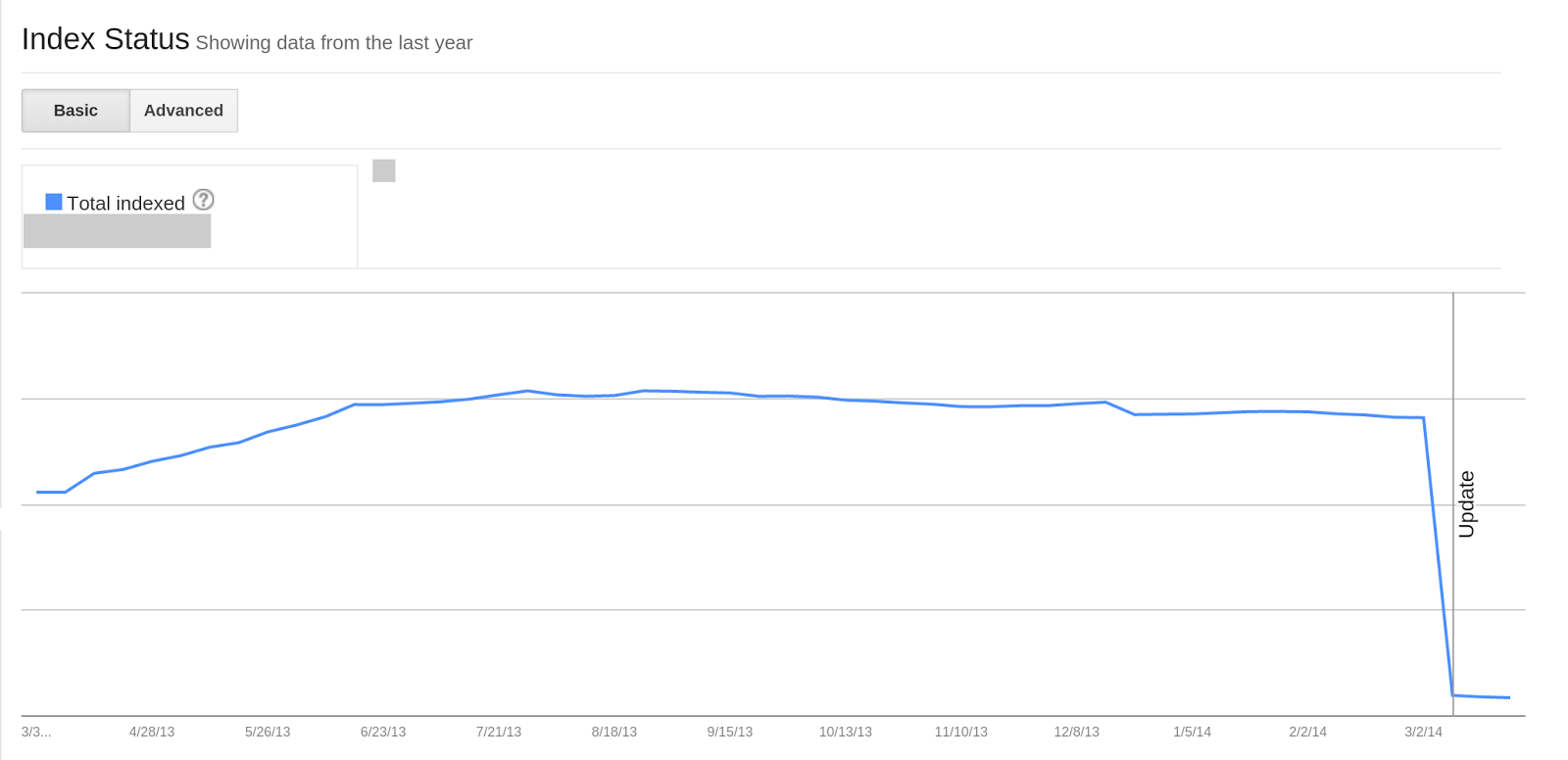

The Google Webmaster Tools Index Status feature reports how many pages on your site are indexed by Google. In the past, we didn’t show index status data for HTTPS websites independently, but rather we’d included everything in the HTTP site’s report. In the last months, we’ve heard from you that you’d like to use Webmaster Tools to track your indexed URLs for sections of your website, including the parts that use HTTPS.
We’ve seen that nearly 10% of all URLs already use a secure connection to transfer data via HTTPS, and we hope to see more webmasters move their websites from HTTP to HTTPS in the future. We’re happy to announce a refinement in the way your site’s index status data is displayed in Webmaster Tools: the Index Status feature now tracks your site’s indexed URLs for each protocol (HTTP and HTTPS) as well as for verified subdirectories.
This makes it easy for you to monitor different sections of your site. For example, the following URLs each show their own data in Webmaster Tools Index Status report, provided they are verified separately:
|
HTTP
|
HTTPS
|
The refined data will be visible for webmasters whose site’s URLs are on HTTPS or who have subdirectories verified, such as https://example.com/folder/. Data for subdirectories will be included in the higher-level verified sites on the same hostname and protocol.
If you have a website on HTTPS or if some of your content is indexed under different subdomains, you will see a change in the corresponding Index Status reports. The screenshots below illustrate the changes that you may see on your HTTP and HTTPS sites’ Index Status graphs for instance:
HTTP site’s Index Status showing drop
HTTPS site’s Index Status showing increase
An “Update” annotation has been added to the Index Status graph for March 9th, showing when we started collecting this data. This change does not affect the way we index your URLs, nor does it have an impact on the overall number of URLs indexed on your domain. It is a change that only affects the reporting of data in Webmaster Tools user interface.
In order to see your data correctly, you will need to verify all existing variants of your site (www., non-www., HTTPS, subdirectories, subdomains) in Google Webmaster Tools. We recommend that your preferred domains and canonical URLs are configured accordingly.
Note that if you wish to submit a Sitemap, you will need to do so for the preferred variant of your website, using the corresponding URLs. Robots.txt files are also read separately for each protocol and hostname.
We hope that you’ll find this update useful, and that it’ll help you monitor, identify and fix indexing problems with your website. You can find additional details in our Index Status Help Center article. As usual, if you have any questions, don’t hesitate to ask in our webmaster Help Forum.
Posted by Zineb Ait Bahajji, WTA, thanks to the Webmaster Tools team.
Introducing the new Webmaster Academy
Webmaster level: Beginner

Our Webmaster Academy is now available with new and targeted content!
Two years ago, Webmaster Academy launched to teach new and beginner webmasters how to make great websites. In addition to adding new content, we’ve now expanded and improved information on three important topics:
- Making a great site that’s valuable to your audience (Module 1)
- Learning how Google sees and understands your site (Module 2)
- Communicating with Google about your site (Module 3)
If you often find yourself overwhelmed by the depth or breadth of our resources, Webmaster Academy will help you understand the basics of creating a website and having it found in Google Search. If you’re an experienced webmaster, you might learn something new too.
Enjoy, learn, and share your feedback!
Posted by Mary Chen, Webmaster Outreach Team
App Engine IP Range Change Notice
Google uses a wide range of IP addresses for its different services, and the addresses may change without notification. Google App Engine is a Platform as a Service offering which hosts a wide variety of 3rd party applications. This post announces changes in the IP address range and headers used by the Google App Engine URLFetch (outbound HTTP) and outbound sockets APIs.
While we recommend that App Engine IP ranges not be used to filter inbound requests, we are aware that some services have created filters that rely on specific addresses. Google App Engine will be changing its IP range beginning this month. Please see these instructions to determine App Engine’s IP range.
Additionally, the HTTP User-Agent header string that historically allowed identification of individual App Engine applications should no longer be relied on to identify the application. With the introduction of outbound sockets for App Engine, applications may now make HTTP requests without using the URLFetch API, and those requests may set a User-Agent of their own choosing.
Posted by the Google App Engine Team
Musical artists: your official tour dates in the Knowledge Graph
Webmaster level: all

When music lovers search for their favorite band on Google, we often show them a Knowledge Graph panel with lots of information about the band, including the band’s upcoming concert schedule. It’s important to fans and artists alike that this schedule be accurate and complete. That’s why we’re trying a new approach to concert listings. In our new approach, all concert information for an artist comes directly from that artist’s official website when they add structured data markup.
If you’re the webmaster for a musical artist’s official website, you have several choices for how to participate:
- You can implement schema.org markup on your site. That’s easier than ever, since we’re supporting the new JSON-LD format (alongside RDFa and microdata) for this feature.
- Even easier, you can install an events widget that has structured data markup built in, such as Bandsintown, BandPage, ReverbNation, Songkick, or GigPress.
- You can label the site’s events with your mouse using Google’s point-and-click webmaster tool: Data Highlighter.
All these options are explained in detail in our Help Center. If you have any questions, feel free to ask in our Webmaster Help forums. So don’t you worry `bout a schema.org/Thing … just mark up your site’s events and let the good schema.org/Times roll!
Posted by Justin Boyan, Product Manager, Google Search
3 tips to find hacking on your site, and ways to prevent and fix it
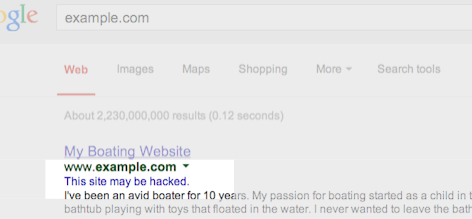
Google shows this message in search results for sites that we believe may have been compromised.You might not think your site is a target for hackers, but it’s surprisingly common. Hackers target large numbers of sites all over the web in order to exploit the sites’ users or reputation.
One common way hackers take advantage of vulnerable sites is by adding spammy pages. These spammy pages are then used for various purposes, such as redirecting users to undesired or harmful destinations. For example, we’ve recently seen an increase in hacked sites redirecting users to fake online shopping sites.
Once you recognize that your website may have been hacked, it’s important to diagnose and fix the problem as soon as possible. We want webmasters to keep their sites secure in order to protect users from spammy or harmful content.
3 tips to help you find hacked content on your site
- Check your site for suspicious URLs or directories
Keep an eye out for any suspicious activity on your site by performing a “site:” search of your site in Google, such as [site:example.com]. Are there any suspicious URLs or directories that you do not recognize?You can also set up a Google Alert for your site. For example, if you set a Google Alert for [site:example.com (viagra|cialis|casino|payday loans)], you’ll receive an email when these keywords are detected on your site.
- Look for unnatural queries on the Search Queries page in Webmaster Tools
The Search Queries page shows Google Web Search queries that have returned URLs from your site. Look for unexpected queries as it can be an indication of hacked content on your site.Don’t be quick to dismiss queries in different languages. This may be the result of spammy pages in other languages placed on your website.
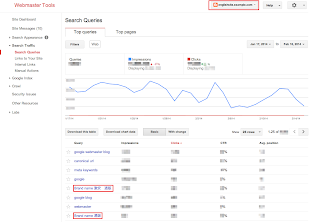
Example of an English site hacked with Japanese content. - Enable email forwarding in Webmaster Tools
Google will send you a message if we detect that your site may be compromised. Messages appear in Webmaster Tools’ Message Center but it’s a best practice to also forward these messages to your email. Keep in mind that Google won’t be able to detect all kinds of hacked content, but we hope our notifications will help you catch things you may have missed.

Tips to fix and prevent hacking
- Stay informed
The Security Issues section in Webmaster Tools will show you hacked pages that we detected on your site. We also provide detailed information to help you fix your hacked site. Make sure to read through this documentation so you can quickly and effectively fix your site. - Protect your site from potential attacks
It’s better to prevent sites from being hacked than to clean up hacked content. Hackers will often take advantage of security vulnerabilities on commonly used website management software. Here are some tips to keep your site safe from hackers: - Always keep the software that runs your website up-to-date.
- If your website management software tools offer security announcements, sign up to get the latest updates.
- If the software for your website is managed by your hosting provider, try to choose a provider that you can trust to maintain the security of your site.
We hope this post makes it easier for you to identify, fix, and prevent hacked spam on your site. If you have any questions, feel free to post in the comments, or drop by the Google Webmaster Help Forum.
If you find suspicious sites in Google search results, please report them using the Spam Report tool.
Posted by Megumi Hitomi, Japanese Search Quality Team
Infinite scroll search-friendly recommendations
Webmaster Level: Advanced
Your site’s news feed or pinboard might use infinite scroll—much to your users’ delight! When it comes to delighting Googlebot, however, that can be another story. With infinite scroll, crawlers cannot always emulate manual user behavior–like scrolling or clicking a button to load more items–so they don’t always access all individual items in the feed or gallery. If crawlers can’t access your content, it’s unlikely to surface in search results.
To make sure that search engines can crawl individual items linked from an infinite scroll page, make sure that you or your content management system produces a paginated series (component pages) to go along with your infinite scroll.

Infinite scroll page is made “search-friendly” when converted to a paginated series — each component page has a similar <title> with rel=next/prev values declared in the <head>.
You can see this type of behavior in action in the infinite scroll with pagination demo created by Webmaster Trends Analyst, John Mueller. The demo illustrates some key search-engine friendly points:
- Coverage: All individual items are accessible. With traditional infinite scroll, individual items displayed after the initial page load aren’t discoverable to crawlers.
- No overlap: Each item is listed only once in the paginated series (i.e., no duplication of items).
Search-friendly recommendations for infinite scroll
- Before you start:
- Chunk your infinite-scroll page content into component pages that can be accessed when JavaScript is disabled.
- Determine how much content to include on each page.
- Be sure that if a searcher came directly to this page, they could easily find the exact item they wanted (e.g., without lots of scrolling before locating the desired content).
- Maintain reasonable page load time.
- Divide content so that there’s no overlap between component pages in the series (with the exception of buffering).
- Structure URLs for infinite scroll search engine processing.
- Each component page contains a full URL. We recommend full URLs in this situation to minimize potential for configuration error.
- Good:
example.com/category?name=fun-items&page=1 - Good:
example.com/fun-items?lastid=567 - Less optimal:
example.com/fun-items#1 - Test that each component page (the URL) works to take anyone directly to the content and is accessible/referenceable in a browser without the same cookie or user history.
- Good:
- Any key/value URL parameters should follow these recommendations:
- Be sure the URL shows conceptually the same content two weeks from now.
- Avoid relative-time based URL parameters:
example.com/category/page.php?name=fun-items&days-ago=3
- Avoid relative-time based URL parameters:
- Create parameters that can surface valuable content to searchers.
- Avoid non-searcher valuable parameters as the primary method to access content:
example.com/fun-places?radius=5&lat=40.71&long=-73.40
- Avoid non-searcher valuable parameters as the primary method to access content:
- Be sure the URL shows conceptually the same content two weeks from now.
- Each component page contains a full URL. We recommend full URLs in this situation to minimize potential for configuration error.
- Configure pagination with each component page containing rel=next and rel=prev values in the <head>. Pagination values in the <body> will be ignored for Google indexing purposes because they could be created with user-generated content (not intended by the webmaster).
- Implement replaceState/pushState on the infinite scroll page. (The decision to use one or both is up to you and your site’s user behavior). That said, we recommend including pushState (by itself, or in conjunction with replaceState) for the following:
- Any user action that resembles a click or actively turning a page.
- To provide users with the ability to serially backup through the most recently paginated content.
- Test!
- Check that page values adjust as the user scrolls up or down. John Mueller’s infinite-scroll-with-pagination site demonstrates the scrolling up/down behavior.
- Verify that pages that are out-of-bounds in the series return a 404 response (i.e.,
example.com/category?name=fun-items&page=999should return a 404 response if there are only 998 pages of content). - Investigate potential usability implications introduced by your infinite scroll implementation.

The example on the left is search-friendly, the right example isn’t — the right example would cause crawling and indexing of duplicative content.
Written, reviewed, or coded by John Mueller, Maile Ohye, and Joachim Kupke
Faceted navigation best (and 5 of the worst) practices
Webmaster Level: Advanced
Faceted navigation, such as filtering by color or price range, can be helpful for your visitors, but it’s often not search-friendly since it creates many combinations of URLs with duplicative content. With duplicative URLs, search engines may not crawl new or updated unique content as quickly, and/or they may not index a page accurately because indexing signals are diluted between the duplicate versions. To reduce these issues and help faceted navigation sites become as search-friendly as possible, we’d like to:
- Provide background and potential issues with faceted navigation
- Highlight worst practices
- Share best practices

Selecting filters with faceted navigation can cause many URL combinations, such as
http://www.example.com/category.php?category=gummy-candies&price=5-10&price=over-10Background
In an ideal state, unique content — whether an individual product/article or a category of products/articles — would have only one accessible URL. This URL would have a clear click path, or route to the content from within the site, accessible by clicking from the homepage or a category page.
Ideal for searchers and Google Search
- Clear path that reaches all individual product/article pages
On the left is potential user navigation on the site (i.e., the click path), on the right are the pages accessed.- One representative URL for category page
http://www.example.com/category.php?category=gummy-candies
Category page for gummy candies- One representative URL for individual product page
http://www.example.com/product.php?item=swedish-fish
Product page for swedish fishUndesirable duplication caused with faceted navigation
- Numerous URLs for the same article/product
Canonical Duplicate example.com/product.php? item=swedish-fishexample.com/product.php? item=swedish-fish&category=gummy-candies&price=5-10Same product page for swedish fish can be available on multiple URLs.
- Numerous category pages that provide little or no value to searchers and search engines)
URL example.com/category.php? category=gummy-candies&taste=sour&price=5-10example.com/category.php? category=gummy-candies&taste=sour&price=over-10Issues
- No added value to Google searchers given users rarely search for [sour gummy candy price five to ten dollars].
- No added value for search engine crawlers that discover same item (“fruit salad”) from parent category pages (either “gummy candies” or “sour gummy candies”).
- Negative value to site owner who may have indexing signals diluted between numerous versions of the same category.
- Negative value to site owner with respect to serving bandwidth and losing crawler capacity to duplicative content rather than new or updated pages.
- No value for search engines (should have 404 response code).
- Negative value to searchers.







Worst (search un-friendly) practices for faceted navigation
Worst practice #1: Non-standard URL encoding for parameters, like commas or brackets, instead of “key=value&” pairs.
Worst practices:
example.com/category?[category:gummy-candy][sort:price-low-to-high][sid:789]
- key=value pairs marked with : rather than =
- multiple parameters appended with [ ] rather than &
example.com/category?category,gummy-candy,,sort,lowtohigh,,sid,789
- key=value pairs marked with a , rather than =
- multiple parameters appended with ,, rather than &
Best practice:
example.com/category?category=gummy-candy&sort=low-to-high&sid=789While humans may be able to decode odd URL parameters, such as “,,”, crawlers have difficulty interpreting URL parameters when they’re implemented in a non-standard fashion. Software engineer on Google’s Crawling Team, Mehmet Aktuna, says “Using non-standard encoding is just asking for trouble.” Instead, connect key=value pairs with an equal sign (=) and append multiple parameters with an ampersand (&).
Worst practice #2: Using directories or file paths rather than parameters to list values that don’t change page content.
Worst practice:
example.com/c123/s789/product?swedish-fish
(where /c123/ is a category, /s789/ is a sessionID that doesn’t change page content)Good practice:
example.com/gummy-candy/product?item=swedish-fish&sid=789(the directory, /gummy-candy/,changes the page content in a meaningful way)Best practice:
example.com/product?item=swedish-fish&category=gummy-candy&sid=789(URL parameters allow more flexibility for search engines to determine how to crawl efficiently)It’s difficult for automated programs, like search engine crawlers, to differentiate useful values (e.g., “gummy-candy”) from the useless ones (e.g., “sessionID”) when values are placed directly in the path. On the other hand, URL parameters provide flexibility for search engines to quickly test and determine when a given value doesn’t require the crawler access all variations.
Common values that don’t change page content and should be listed as URL parameters include:
- Session IDs
- Tracking IDs
- Referrer IDs
- Timestamp
Worst practice #3: Converting user-generated values into (possibly infinite) URL parameters that are crawlable and indexable, but not useful in search results.
Worst practices (e.g., user-generated values like longitude/latitude or “days ago” as crawlable and indexable URLs):
example.com/find-a-doctor?radius=15&latitude=40.7565068&longitude=-73.9668408
example.com/article?category=health&days-ago=7Best practices:
example.com/find-a-doctor?city=san-francisco&neighborhood=soma
example.com/articles?category=health&date=january-10-2014Rather than allow user-generated values to create crawlable URLs — which leads to infinite possibilities with very little value to searchers — perhaps publish category pages for the most popular values, then include additional information so the page provides more value than an ordinary search results page. Alternatively, consider placing user-generated values in a separate directory and then robots.txt disallow crawling of that directory.
example.com/filtering/find-a-doctor?radius=15&latitude=40.7565068&longitude=-73.9668408example.com/filtering/articles?category=health&days-ago=7with robots.txt:
User-agent: *
Disallow: /filtering/Worst practice #4: Appending URL parameters without logic.
Worst practices:
example.com/gummy-candy/lollipops/gummy-candy/gummy-candy/product?swedish-fishexample.com/product?cat=gummy-candy&cat=lollipops&cat=gummy-candy&cat=gummy-candy&item=swedish-fishBetter practice:
example.com/gummy-candy/product?item=swedish-fishBest practice:
example.com/product?item=swedish-fish&category=gummy-candyExtraneous URL parameters only increase duplication, causing less efficient crawling and indexing. Therefore, consider stripping unnecessary URL parameters and performing your site’s “internal housekeeping” before generating the URL. If many parameters are required for the user session, perhaps hide the information in a cookie rather than continually append values like
cat=gummy-candy&cat=lollipops&cat=gummy-candy&…Worst practice #5: Offering further refinement (filtering) when there are zero results.
Worst practice:
Allowing users to select filters when zero items exist for the refinement.
Refinement to a page with zero results (e.g.,price=over-10) is allowed even though it frustrates users and causes unnecessary issues for search engines.Best practice
Only create links/URLs when it’s a valid user-selection (items exist). With zero items, grey out filtering options. To further improve usability, consider adding item counts next to each filter.
Refinement to a page with zero results (e.g.,price=over-10) isn’t allowed, preventing users from making an unnecessary click and search engine crawlers from accessing a non-useful page.Prevent useless URLs and minimize the crawl space by only creating URLs when products exist. This helps users to stay engaged on your site (fewer clicks on the back button when no products exist), and helps minimize potential URLs known to crawlers. Furthermore, if a page isn’t just temporarily out-of-stock, but is unlikely to ever contain useful content, consider returning a 404 status code. With the 404 response, you can include a helpful message to users with more navigation options or a search box to find related products.


Best practices for new faceted navigation implementations or redesigns
New sites that are considering implementing faceted navigation have several options to optimize the “crawl space” (the totality of URLs on your site known to Googlebot) for unique content pages, reduce crawling of duplicative pages, and consolidate indexing signals.
- Determine which URL parameters are required for search engines to crawl every individual content page (i.e., determine what parameters are required to create at least one click-path to each item). Required parameters may include
item-id,category-id,page, etc.- Determine which parameters would be valuable to searchers and their queries, and which would likely only cause duplication with unnecessary crawling or indexing. In the candy store example, I may find the URL parameter “
taste” to be valuable to searchers for queries like [sour gummy candies] which could show the resultexample.com/category.php?category=gummy-candies&taste=sour. However, I may consider the parameter “price” to only cause duplication, such ascategory=gummy-candies&taste=sour&price=over-10. Other common examples:
- Valuable parameters to searchers:
item-id,category-id,name,brand…- Unnecessary parameters:
session-id,price-range…- Consider implementing one of several configuration options for URLs that contain unnecessary parameters. Just make sure that the unnecessary URL parameters are never required in a crawler or user’s click path to reach each individual product!
- Option 1: rel=”nofollow” internal links
Make all unnecessary URLs links rel=“nofollow.” This option minimizes the crawler’s discovery of unnecessary URLs and therefore reduces the potentially explosive crawl space (URLs known to the crawler) that can occur with faceted navigation. rel=”nofollow” doesn’t prevent the unnecessary URLs from being crawled (only a robots.txt disallow prevents crawling). By allowing them to be crawled, however, you can consolidate indexing signals from the unnecessary URLs with a searcher-valuable URL by adding rel=”canonical” from the unnecessary URL to a superset URL (e.g.
example.com/category.php?category=gummy-candies&taste=sour&price=5-10can specify arel=”canonical”to the superset sour gummy candies view-all page atexample.com/category.php?category=gummy-candies&taste=sour&page=all).- Option 2: Robots.txt disallow
For URLs with unnecessary parameters, include a
/filtering/directory that will be robots.txt disallow’d. This lets all search engines freely crawl good content, but will prevent crawling of the unwanted URLs. For instance, if my valuable parameters were item, category, and taste, and my unnecessary parameters were session-id and price. I may have the URL:example.com/category.php?category=gummy-candies
which could link to another URL valuable parameter such as taste:example.com/category.php?category=gummy-candies&taste=sour.
but for the unnecessary parameters, such as price, the URL includes a predefined directory,/filtering/:example.com/filtering/category.php?category=gummy-candies&price=5-10
which is then robots.txt disallowed
User-agent: *
Disallow: /filtering/- Option 3: Separate hosts
If you’re not using a CDN (sites using CDNs don’t have this flexibility easily available in Webmaster Tools), consider placing any URLs with unnecessary parameters on a separate host — for example, creating main host
www.example.comand secondary host,www2.example.com. On the secondary host (www2), set the Crawl rate in Webmaster Tools to “low” while keeping the main host’s crawl rate as high as possible. This would allow for more full crawling of the main host URLs and reduces Googlebot’s focus on your unnecessary URLs.
- Be sure there remains at least one click path to all items on the main host.
- If you’d like to consolidate indexing signals, consider adding rel=”canonical” from the secondary host to a superset URL on the main host (e.g.
www2.example.com/category.php?category=gummy-candies&taste=sour&price=5-10may specify a rel=”canonical” to the superset “sour gummy candies” view-all page,www.example.com/category.php?category=gummy-candies&taste=sour&page=all).
- Prevent clickable links when no products exist for the category/filter.
- Add logic to the display of URL parameters.
- Remove unnecessary parameters rather than continuously append values.
- Avoid
example.com/product?cat=gummy-candy&cat=lollipops&cat=gummy-candy&item=swedish-fish)- Help the searcher experience by keeping a consistent parameter order based on searcher-valuable parameters listed first (as the URL may be visible in search results) and searcher-irrelevant parameters last (e.g., session ID).
- Avoid
example.com/category.php?session-id=123&tracking-id=456&category=gummy-candies&taste=sour- Improve indexing of individual content pages with rel=”canonical” to the preferred version of a page. rel=”canonical” can be used across hostnames or domains.
- Improve indexing of paginated content (such as page=1 and page=2 of the category “gummy candies”) by either:
- Adding rel=”canonical” from individual component pages in the series to the category’s “view-all” page (e.g. page=1, page=2, and page=3 of “gummy candies” with rel=”canonical” to
category=gummy-candies&page=all) while making sure that it’s still a good searcher experience (e.g., the page loads quickly).- Using pagination markup with rel=”next” and rel=”prev” to consolidate indexing properties, such as links, from the component pages/URLs to the series as a whole.
- Be sure that if using JavaScript to dynamically sort/filter/hide content without updating the URL, there still exists URLs on your site that searchers would find valuable, such as main category and product pages that can be crawled and indexed. For instance, avoid using only the homepage (i.e., one URL) for your entire site with JavaScript to dynamically change content with user navigation — this would unfortunately provide searchers with only one URL to reach all of your content. Also, check that performance isn’t negatively affected with dynamic filtering, as this could undermine the user experience.
- Include only canonical URLs in Sitemaps.
Best practices for existing sites with faceted navigation
First, know that the best practices listed above (e.g., rel=”nofollow” for unnecessary URLs) still apply if/when you’re able to implement a larger redesign. Otherwise, with existing faceted navigation, it’s likely that a large crawl space was already discovered by search engines. Therefore, focus on reducing further growth of unnecessary pages crawled by Googlebot and consolidating indexing signals.
- Use parameters (when possible) with standard encoding and key=value pairs.
- Verify that values that don’t change page content, such as session IDs, are implemented as standard key=value pairs, not directories
- Prevent clickable anchors when products exist for the category/filter (i.e., don’t allow clicks or URLs to be created when no items exist for the filter)
- Add logic to the display of URL parameters
- Remove unnecessary parameters rather than continuously append values (e.g., avoid
example.com/product?cat=gummy-candy&cat=lollipops&cat=gummy-candy&item=swedish-fish)- Help the searcher experience by keeping a consistent parameter order based on searcher-valuable parameters listed first (as the URL may be visible in search results) and searcher-irrelevant parameters last (e.g., avoid
example.com/category?session-id=123&tracking-id=456&category=gummy-candies&taste=sour&in favor ofexample.com/category.php?category=gummy-candies&taste=sour&session-id=123&tracking-id=456)- Configure Webmaster Tools URL Parameters if you have strong understanding of the URL parameter behavior on your site (make sure that there is still a clear click path to each individual item/article). For instance, with URL Parameters in Webmaster Tools, you can list the parameter name, the parameters effect on the page content, and how you’d like Googlebot to crawl URLs containing the parameter.
URL Parameters in Webmaster Tools allows the site owner to provide information about the site’s parameters and recommendations for Googlebot’s behavior.- Be sure that if using JavaScript to dynamically sort/filter/hide content without updating the URL, there still exists URLs on your site that searchers would find valuable, such as main category and product pages that can be crawled and indexed. For instance, avoid using only the homepage (i.e., one URL) for your entire site with JavaScript to dynamically change content with user navigation — this would unfortunately provide searchers with only one URL to reach all of your content. Also, check that performance isn’t negatively affected with dynamic filtering, as this could undermine the user experience.
- Improve indexing of individual content pages with rel=”canonical” to the preferred version of a page. rel=”canonical” can be used across hostnames or domains.
- Improve indexing of paginated content (such as page=1 and page=2 of the category “gummy candies”) by either:
- Adding rel=”canonical” from individual component pages in the series to the category’s “view-all” page (e.g. page=1, page=2, and page=3 of “gummy candies” with rel=”canonical” to
category=gummy-candies&page=all) while making sure that it’s still a good searcher experience (e.g., the page loads quickly).- Using pagination markup with rel=”next” and rel=”prev” to consolidate indexing properties, such as links, from the component pages/URLs to the series as a whole.
- Include only canonical URLs in Sitemaps.

Remember that commonly, the simpler you can keep it, the better. Questions? Please ask in our Webmaster discussion forum.
Written by Maile Ohye, Developer Programs Tech Lead, and Mehmet Aktuna, Crawl Team
Affiliate programs and added value
Webmaster level: All
Our quality guidelines warn against running a site with thin or scraped content without adding substantial added value to the user. Recently, we’ve seen this behavior on many video sites, particularly in the adult industry, but also elsewhere. These sites display content provided by an affiliate program—the same content that is available across hundreds or even thousands of other sites.
If your site syndicates content that’s available elsewhere, a good question to ask is: “Does this site provide significant added benefits that would make a user want to visit this site in search results instead of the original source of the content?” If the answer is “No,” the site may frustrate searchers and violate our quality guidelines. As with any violation of our quality guidelines, we may take action, including removal from our index, in order to maintain the quality of our users’ search results. If you have any questions about our guidelines, you can ask them in our Webmaster Help Forum.
Posted by Chris Nelson, Search Quality Team
A new Googlebot user-agent for crawling smartphone content
Webmaster level: Advanced
Over the years, Google has used different crawlers to crawl and index content for feature phones and smartphones. These mobile-specific crawlers have all been referred to as Googlebot-Mobile. However, feature phones and smartphones have considerably different device capabilities, and we’ve seen cases where a webmaster inadvertently blocked smartphone crawling or indexing when they really meant to block just feature phone crawling or indexing. This ambiguity made it impossible for Google to index smartphone content of some sites, or for Google to recognize that these sites are smartphone-optimized.
A new Googlebot for smartphones
To clarify the situation and to give webmasters greater control, we’ll be retiring “Googlebot-Mobile” for smartphones as a user agent starting in 3-4 weeks’ time. From then on, the user-agent for smartphones will identify itself simply as “Googlebot” but will still list “mobile” elsewhere in the user-agent string. Here are the new and old user-agents:
The new Googlebot for smartphones user-agent:Mozilla/5.0 (iPhone; CPU iPhone OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5376e Safari/8536.25 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
The Googlebot-Mobile for smartphones user-agent we will be retiring soon:Mozilla/5.0 (iPhone; CPU iPhone OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5376e Safari/8536.25 (compatible; Googlebot-Mobile/2.1; +http://www.google.com/bot.html)
This change affects only Googlebot-Mobile for smartphones. The user-agent of the regular Googlebot does not change, and the remaining two Googlebot-Mobile crawlers will continue to refer to feature phone devices in their user-agent strings; for reference, these are:
Regular Googlebot user-agent:Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
The two Googlebot-Mobile user-agents for feature phones:
SAMSUNG-SGH-E250/1.0 Profile/MIDP-2.0 Configuration/CLDC-1.1 UP.Browser/6.2.3.3.c.1.101 (GUI) MMP/2.0 (compatible; Googlebot-Mobile/2.1; +http://www.google.com/bot.html)DoCoMo/2.0 N905i(c100;TB;W24H16) (compatible; Googlebot-Mobile/2.1; +http://www.google.com/bot.html)
You can test your site using the Fetch as Google feature in Webmaster Tools, and you can see a full list of our existing crawlers in the Help Center.
Crawling and indexing
Please note this important implication of the user-agent update: The new Googlebot for smartphones crawler will follow robots.txt, robots meta tag, and HTTP header directives for Googlebot instead of Googlebot-Mobile. For example, when the new crawler is deployed, this robots.txt directive will block all crawling by the new Googlebot for smartphones user-agent, and also the regular Googlebot:
User-agent: Googlebot
Disallow: /
This robots.txt directive will block crawling by Google’s feature phone crawlers:
User-agent: Googlebot-Mobile
Disallow: /
Based on our internal analyses, this update affects less than 0.001% of URLs while giving webmasters greater control over the crawling and indexing of their content. As always, if you have any questions, you can:
- Read our recommendations for building smartphone-optimized sites
- Learn more about controlling Googlebot crawling and indexing
- Ask in our Webmaster help forums or visit one of our Webmaster Central office hours hangouts.
Posted by Zhijian He, Smartphone search engineer
Changes in crawl error reporting for redirects
Webmaster level: intermediate-advancedIn the past, we have seen occasional confusion by webmasters regarding how crawl errors on redirecting pages were shown in Webmaster Tools. It’s time to make this a bit clearer and easier to diagnose! While it used…
Google Publisher Plugin beta: Bringing our publisher products to WordPress
Cross-posted from the Inside AdSense blog.
We’ve heard from many publishers using WordPress that they’re looking for an easier way to work with Google products within the platform. Today, we’re excited to share the beta release of our official Google Publisher Plugin, which adds new functionality to publishers’ WordPress websites. If you own your own domain and power it with WordPress, this new plugin will give you access to a few Google services — and all within WordPress.
Please keep in mind that because this is a beta release, we’re still fine-tuning the plugin to make sure it works well on the many WordPress sites out there. We’d love for you to try it now and share your feedback on how it works for your site.
This first version of the Google Publisher Plugin currently supports two Google products:
- Google AdSense: Earn money by placing ads on your website. The plugin links your WordPress site to your AdSense account and makes it easier to place ads on your site — without needing to manually modify any HTML code.
- Google Webmaster Tools: Webmaster Tools provides you with detailed reports about your pages’ visibility on Google. The plugin allows you to verify your site on Webmaster Tools with just one click.
Visit the WordPress.org plugin directory to download the new plugin and give it a try. For more information about the plugin and how to use it, please visit our Help Center. We look forward to hearing your feedback!
Posted by Michael Smith – Product Manager
More detailed search queries in Webmaster Tools
Webmaster level: intermediateTo help jump-start your year and make metrics for your site more actionable, we’ve updated one of the most popular features in Webmaster Tools: data in the search queries feature will no longer be rounded / bucketed. This c…
Improved Search Queries stats for separate mobile sites
Webmaster Level: All
Search Queries in Webmaster Tools just became more cohesive for those who manage a mobile site on a separate URL from desktop, such as mobile on m.example.com and desktop on www. In Search Queries, when you view your m. site* and set Filters to “Mobile,” from Dec 31, 2013 onwards, you’ll now see:
- Queries where your m. pages appeared in search results for mobile browsers
- Queries where Google applied Skip Redirect. This means that, while search results displayed the desktop URL, the user was automatically directed to the corresponding m. version of the URL (thus saving the user from latency of a server-side redirect).

Skip Redirect information (impressions, clicks, etc.) calculated with mobile site.
Prior to this Search Queries improvement, Webmaster Tools reported Skip Redirect impressions with the desktop URL. Now we’ve consolidated information when Skip Redirect is triggered, so that impressions, clicks, and CTR are calculated solely with the verified m. site, making your mobile statistics more understandable.
Best practices if you have a separate m. site
Here are a few search-friendly recommendations for those publishing content on a separate m. site:
- Follow our advice on Building Smartphone-Optimized Websites
- On the desktop page, add a special link rel=”alternate” tag pointing to the corresponding mobile URL. This helps Googlebot discover the location of your site’s mobile pages.
- On the mobile page, add a link rel=”canonical” tag pointing to the corresponding desktop URL.
- Use the
HTTP Vary: User-Agentheader if your servers automatically redirect users based on their user agent/device. - Verify ownership of both the desktop (www) and mobile (m.) sites in Webmaster Tools for improved communication and troubleshooting information specific to each site.
* Be sure you’ve verified ownership for your mobile site!
Written by Maile Ohye, Developer Programs Tech Lead
So long, 2013, and thanks for all the fish
Now that 2013 is almost over, we’d love to take a quick look back, and venture a glimpse into the future. Some of the important topics on our blog from 2013 were around mobile, internationalization, and search quality in general. Here are some of the m…
Switching to the new website verification API
Webmaster level: advanced Just over a year ago we introduced a new API for website verification for Google services. In the spirit of keeping things simple and focusing our efforts, we’ve decided to deprecate the old verification API method on Match 31…
Improving URL removals on third-party sites
Webmaster level: allContent on the Internet changes or disappears, and occasionally it’s helpful to have search results for it updated quickly. Today we launched our improved public URL removal tool to make it easier to request updates based on changes…
Structured Data dashboard: new markup error reports for easier debugging
Since we launched the Structured Data dashboard last year, it has quickly become one of the most popular features in Webmaster Tools. We’ve been working to expand it and make it even easier to debug issues so that you can see how Google understands the marked-up content on your site.
Starting today, you can see items with errors in the Structured Data dashboard. This new feature is a result of a collaboration with webmasters, whom we invited in June to>register as early testers of markup error reporting in Webmaster Tools. We’ve incorporated their feedback to improve the functionality of the Structured Data dashboard.
An “item” here represents one top-level structured data element (nested items are not counted) tagged in the HTML code. They are grouped by data type and ordered by number of errors:

We’ve added a separate scale for the errors on the right side of the graph in the dashboard, so you can compare items and errors over time. This can be useful to spot connections between changes you may have made on your site and markup errors that are appearing (or disappearing!).
Our data pipelines have also been updated for more comprehensive reporting, so you may initially see fewer data points in the chronological graph.
How to debug markup implementation errors
- To investigate an issue with a specific content type, click on it and we’ll show you the markup errors we’ve found for that type. You can see all of them at once, or filter by error type using the tabs at the top:
- Check to see if the markup meets the implementation guidelines for each content type. In our example case (events markup), some of the items are missing a
startDateornameproperty. We also surface missing properties for nested content types (e.g. a review item inside a product item) — in this case, this is thelowpriceproperty. - Click on URLs in the table to see details about what markup we’ve detected when we crawled the page last and what’s missing. You’ll can also use the “Test live data” button to test your markup in the Structured Data Testing Tool. Often when checking a bunch of URLs, you’re likely to spot a common issue that you can solve with a single change (e.g. by adjusting a setting or template in your content management system).
- Fix the issues and test the new implementation in the Structured Data Testing Tool. After the pages are recrawled and reprocessed, the changes will be reflected in the Structured Data dashboard.


We hope this new feature helps you manage the structured data markup on your site better. We will continue to add more error types in the coming months. Meanwhile, we look forward to your comments and questions here or in the dedicated Structured Data section of the Webmaster Help forum.
Posted by Mariya Moeva, Webmaster Trends Analyst
Checklist and videos for mobile website improvement
Webmaster Level: Intermediate to Advanced
Unsure where to begin improving your smartphone website? Wondering how to prioritize all the advice? We just published a checklist to help provide an efficient approach to mobile website improvement. Several topics in the checklist link to a relevant business case or study, other topics include a video explaining how to make data from Google Analytics and Webmaster Tools actionable during the improvement process. Copied below are shortened sections of the full checklist. Please let us know if there’s more you’d like to see, or if you have additional topics for us to include.
Step 1: Stop frustrating your customers
- Remove cumbersome extra windows from all mobile user-agents | Google recommendation, Article
- JavaScript pop-ups that can be difficult to close.
- Overlays, especially to download apps (instead consider a banner such as iOS 6+ Smart App Banners or equivalent, side navigation, email marketing, etc.).
- Survey requests prior to task completion.
- Provide device-appropriate functionality
- Remove features that require plugins or videos not available on a user’s device (e.g., Adobe Flash isn’t playable on an iPhone or on Android versions 4.1 and higher). | Business case
- Serve tablet users the desktop version (or if available, the tablet version). | Study
- Check that full desktop experience is accessible on mobile phones, and if selected, remains in full desktop version for duration of the session (i.e., user isn’t required to select “desktop version” after every page load). | Study
- Correct high traffic, poor user-experience mobile pages
How to correct high-traffic, poor user-experience mobile pages with data from Google Analytics bounce rate and events (slides)
- Make quick fixes in performance (and continue if behind competition) | Business case
How to make quick fixes in mobile site performance and compare your site to the competition (slides)
To see all topics in “Stop frustrating your customers,” please see the full Checklist for mobile website improvement.
Step 2: Facilitate task completion
- Optimize crawling, indexing, and the searcher experience | Business case
- Unblock resources (CSS, JavaScript) that are robots.txt disallowed.
- Implement search-engine best practices given your mobile implementation:
- Responsive design: Be sure to include CSS
@mediaquery. - Separate mobile site: Add
rel=alternate mediaandrel=canonical, as well asVary: User-AgentHTTP Header which helps Google implement Skip Redirect. - Dynamic serving: Include
Vary: User-AgentHTTP header.
- Responsive design: Be sure to include CSS
- Optimize popular mobile persona workflows for your site
How to optimize popular mobile workflows using Google Webmaster Tools and Google Analytics (slides)
Step Three: Convert customers into fans!
- Consider search integration points with mobile apps | Announcement, Information
- Brainstorm new ways to provide value
- Build for mobile behavior, such as the in-store shopper. | Business case
- Leverage smartphone GPS, camera, accelerometer.
- Increase sharing or social behavior. | Business case
- Consider intuitive/fun tactile functionality with swiping, shaking, tapping.
Written by Maile Ohye, Developer Programs Tech Lead
Smartphone crawl errors in Webmaster Tools
Webmaster level: all
Some smartphone-optimized websites are misconfigured in that they don’t show searchers the information they were seeking. For example, smartphone users are shown an error page or get redirected to an irrelevant page, but desktop users are shown the content they wanted. Some of these problems, detected by Googlebot as crawl errors, significantly hurt your website’s user experience and are the basis of some of our recently-announced ranking changes for smartphone search results.
Starting today, you can use the expanded Crawl Errors feature in Webmaster Tools to help identify pages on your sites that show these types of problems. We’re introducing a new Smartphone errors tab where we share pages we’ve identified with errors only found with Googlebot for smartphones.

Some of the errors we share include:
-
Server errors: A server error is when Googlebot got an HTTP error status code when it crawled the page.
-
Not found errors and soft 404s: A page can show a “not found” message to Googlebot, either by returning an HTTP 404 status code or when the page is detected as a soft error page.
-
Faulty redirects: A faulty redirect is a smartphone-specific error that occurs when a desktop page redirects smartphone users to a page that is not relevant to their query. A typical example is when all pages on the desktop site redirect smartphone users to the homepage of the smartphone-optimized site.
-
Blocked URLs: A blocked URL is when the site’s robots.txt explicitly disallows crawling by Googlebot for smartphones. Typically, such smartphone-specific robots.txt disallow directives are erroneous. You should investigate your server configuration if you see blocked URLs reported in Webmaster Tools.
Fixing any issues shown in Webmaster Tools can make your site better for users and help our algorithms better index your content. You can learn more about how to build smartphone websites and how to fix common errors. As always, please ask in our forums if you have any questions.
Posted by Pierre Far, Webmaster Trends Analyst